
AI Agents Made Tribal Knowledge Executable
Why the next platform problem in engineering isn't the model. It's the harness around it.

Most engineering organizations now have a cursorrules file, a CLAUDE.md, a half-written copilot-instructions.md, and a Teams thread from six months ago that contains the only correct description of how the team actually ships code.
Coding agents amplify whatever they can read.
If the guidance is stale, the agent is stale. If the Cursor rule disagrees with the Copilot instruction file, the agent disagrees with itself. If the only correct answer lives in a senior engineer’s head, the agent will not know it.
At enterprise scale, that gap is where quality, reliability, and trust in AI tooling start to break down.
At Blue Yonder, the Platform Experience teams built a shared AI standards system. One canonical source of truth for how we code, review, observe, debug, and ship, distributed into the repositories and tools where engineers and agents actually work.
The interesting part is not the markdown. It is what happens when tribal knowledge becomes executable, when agents and engineers operate from the same definition of how work gets done.
The Old Problem
I lead Experience Integrity at Blue Yonder. The work is about keeping the experience layer architecturally sound, observable, reliable, and trustworthy at release across many teams and systems.
Most of that work depends on shared practice. How branches and pull requests flow. What “green” actually means. How to read a distributed trace. When an RCA is evidence-backed instead of just plausible. Why do certain security and quality gates exist. How an agent should behave when CI, review comments, and code-quality checks are all in motion at once.
For years, that kind of knowledge lived in three places at once: a wiki page nobody fully trusted, a senior engineer’s head, and a Teams thread from a Tuesday in 2024. New engineers learned it by osmosis. Experienced engineers carried it as judgment. AI assistants absorbed very little of it.
Then the tools changed
Cursor, GitHub Copilot, Claude Code, Codex, Copilot CLI, PR reviewers, and task-specific agents all entered the workflow. Suddenly the tribal knowledge problem was no longer only an onboarding problem. It was an execution problem.
The agents weren’t ineffective because the models were weak, they failed because the organization hadn’t made its operating knowledge readable.
A Concrete Example
Pull request monitoring is a good example.
The human expectation was clear to a few of us. When a PR is open, you do not wait passively for CI to finish if Copilot or another reviewer has already left actionable comments. You watch CI, review threads, and quality gates together. If a thread is valid, you fix it, reply, resolve it, push, and start watching the new commit. If a code-quality gate reports new issues, you treat it like a failing check. You keep going until checks are green and threads are resolved, or until a human-owned blocker remains.
That rule sounds obvious once stated. It was not obvious to most agents. One tool would stop after posting the PR link. Another would wait for CI and ignore review threads. Another would read comments but never resolve them. Another would call the PR “green” while a quality gate was still action-required.
The issue was not intelligence. It was missing institutional context.
Once the workflow was written canonically, every tool had access to the same operating rule. Cursor, Copilot, Claude Code, Codex, and humans could all read the same definition of done.
That is the difference between an agent guessing and an agent operating.
What This Is Called
The clearest public framing I have seen is harness engineering, a term Birgitta Böckeler used on martinfowler.com. A coding agent is not just a model. It is a model plus the harness around it. Prompts, rules, skills, tools, tests, linters, review loops, and runtime feedback.
The split she draws is useful:
Feedforward. Guidance that shapes the agent before it acts: instructions, rules, skills, examples, routing policy.
Feedback. Signals that catch or correct the work after the agent acts: tests, linters, code review, CI, observability, quality gates.
What we built is mainly the feedforward side: a shared, versioned, multi-tool harness for engineering practice.
The feedback side stays where it should. CI, branch protection, static analysis, security scanning, PR review, runtime telemetry, incident workflows. The standards repository does not replace those systems. It gives agents and engineers the shared operating model needed to use them correctly.
Pieces of this pattern exist all over the industry. Cursor rules, Anthropic Skills, OpenAI’s AGENTS.md convention, Copilot instructions, .clinerules, Backstage golden paths, and internal platform playbooks all point in the same direction. What’s discussed less often is the multi-tool, multi-repo version: a distributed feedforward harness with a merge contract, validation, and a clear rollout path.
The phrase I keep coming back to is AI standards as a platform.
What We Built
A standards repository that separates truth from tool formatting.
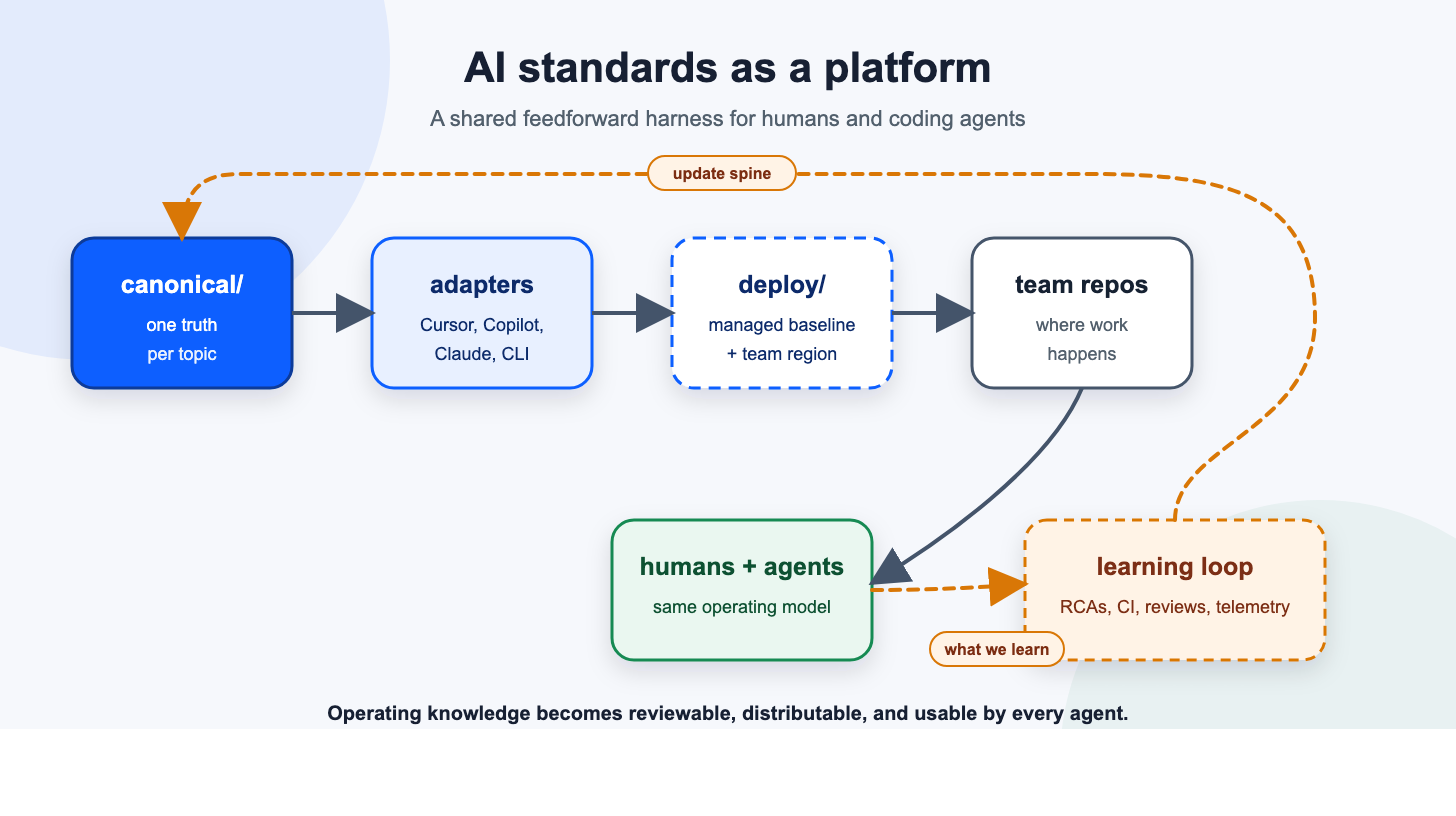
The canonical layer holds the actual guidance. Coding standards, GitHub practices, TypeScript and React patterns, RCA workflows, observability guidance, tool usage, and model-routing policy.
The shims translate that content into the shapes each tool expects. Cursor rules, Cursor skills, GitHub Copilot instructions, AGENTS.md, CLAUDE.md, and CLI-facing guidance. The tool-specific files do not invent new truth. They adapt one truth to the surface where the agent runs.
Shims are intentionally thin. The canonical file might say “never --legacy-peer-deps; never use TypeScript any; security scanning runs through BlackDuck, not npm audit.” The Cursor rule references the same line. The Copilot instructions reference the same line. The AGENTS.md references the same line. There is one place to change the rule, and every tool has the same source to draw from.
The deploy package is what lands in team repos. It includes a managed region and a team-owned region. The platform can refresh the baseline without clobbering local context, and teams can add repo-specific guidance without forking the standard.
That ownership boundary is not a detail; it’s the reason the system works. Central standards fail when they erase local reality. Local guidance fails when it drifts from shared practice. The managed-region contract lets both exist.
When a team genuinely disagrees with the canonical answer, the protocol is to propose a change to the canonical file rather than override it locally. If the disagreement is real, the standard improves for everyone. If it is local-only, that belongs in the team region, with a short note on why. Either way, the conflict surfaces in a pull request instead of silently fragmenting the ecosystem.
What We Considered and Rejected
A few choices shaped the design more than any of the wins did.
A monorepo of all standards instead of a distribution. Easier to author, harder to live with. Teams need standards visible inside their own repo at clone time, not behind a link they have to remember to open.
A vendor-specific format as the primary source of truth. Picking Cursor rules or Copilot instructions as the source of truth would have been faster on day one and a tax forever after. Tools turn over. The truth should not.
A single big prompt. Tempting, but it doesn’t version, review, or distribute well. It also conflates topics with different owners. Coding standards, observability, and incident response shouldn’t live in one wall of text.
Fine-tuning a small model first. More glamorous, but the wrong order. Bake knowledge into weights only after you can write it down, evaluate it, and prove it changes behavior. Local model experiments are interesting, but not the place to start at organizational scale.
The point of these decisions is not that they were obvious. They were not. They were made by a team willing to take the slower, more durable path.
What Changed
The biggest change was not that agents became perfect. They did not. Their mistakes became less random.
When an agent made a bad call, we asked a better question. Did the model miss the instruction, or did the organization fail to write it down? That distinction matters. The first is a model limitation. The second is an engineering backlog item.
Even before we had a formal evaluation suite, practical improvements started to emerge.
Onboarding became less dependent on osmosis. A new engineer can open a repo and see the same expectations an experienced engineer would explain. PR flow, quality gates, observability conventions, RCA expectations, how local credentials are handled safely.
Tool drift became easier to control. A Cursor rule, a Copilot instruction file, and a Claude-specific note used to disagree within a week. Now the canonical file is the source of truth, and the adapters stay thin by design.
Tribal knowledge became reviewable. “How we monitor a PR” or “what an RCA must contain” is no longer only a practice passed between people. It is a file with a commit history, owners, linting, and distribution.
The standards became improvable. Every incident, confused agent behavior, bad review suggestion, or failed rollout can now feed back into the harness.
We are still early in measuring impact. I would not claim that a standards harness magically makes agents reliable. It does something more modest and more useful: it turns repeated confusion into something we can inspect. When an agent misses a rule, we can decide whether the rule was absent, unclear, buried in the wrong place, or contradicted by a local instruction. That gives us an engineering loop instead of a shrug.
How the Spine Stays Current
The biggest risk with any central standards repository is that it goes stale. If updating the canonical file is harder than telling a teammate the new rule in chat, the chat wins, and within a quarter the spine is lying.
A few habits keep this honest.
Contributing must be cheaper than working around it. Pull requests to the canonical file are small, encouraged, and reviewed quickly. If the friction to update a standard is higher than the friction to ignore it, the system has already failed.
Authorship is distributed. The platform team owns the marker boundary and the distribution. Subject-matter owners across teams own the content of the topics they know best. Observability standards do not need to wait on a single human bottleneck.
Real signals drive updates. Incidents, RCAs, repeated review comments, and recurring CI failures are the inputs. When a problem shows up twice, the canonical file is where the lesson lands. The harness improves the same way the codebase does, with evidence.
The distributor is not the source of truth. Teams can read the standards repo directly at any time. If something is wrong upstream, they see it before the next sync. Nothing is hidden in a build step.
This is the part most “AI coding standards” efforts skip, and it is the part that decides whether the system is alive in six months or ornamental.
What Comes Next
A few directions, ordered from practical to speculative.
Tighter feedback loops. If an incident shows the RCA guidance is weak, the standards should change. If a code-quality gate catches the same mistake repeatedly, the feedforward layer should teach agents to avoid it before CI does. If agents consistently mishandle a PR state, the workflow should become more explicit.
Not all failures can be codified. When senior reviewers catch architecturally wrong code that no rule would have flagged, that judgment becomes the next canonical update. The harness gets better, but it never replaces taste.
Evaluation. A harness is only useful if it changes behavior. We need ways to test whether one version of the standards causes agents to make better decisions than another. Sample tasks, expected behaviors, regression cases, maybe PR-review simulations.
Model routing as policy. Not every task deserves the same agent shape. Some work should take a fast, direct path. Some require deeper investigation. Some benefits from orchestrated subagents. This should be defined as policy and evaluated over time, not left to individual preference.
Local fine-tuned models on top, eventually. A governed harness is the foundation. On top of it, targeted smaller models or retrieval systems for style, classification, and decision support can earn their place. The harness stays inspectable, current, and reversible. The model only assists where it has been measured to help.
The Bigger Picture
At Blue Yonder, this standards repository is one part of a larger set of agents and harnesses. PR monitoring, RCA, observability, quality gates, operational support. Each harness has a different job. The standards layer gives them a shared language.
Without that layer, every agent invents its own definition of done. Every tool grows its own local folklore. Every repo becomes a slightly different training ground for the same mistakes.
With it, the things senior engineers know can start moving through the system as shared infrastructure. Not as a manifesto, but as code, with owners, history, and a distribution path.
This kind of work is the platform job, and it gets done because an organization decides it is worth doing well. Blue Yonder funded the time to do it carefully, and the Platform Experience teams who use it daily are the ones who keep it honest. A repo like this earns its keep only when the people downstream of it are better off.
If you sit in any of those seats, the question is not whether AI agents change how we ship. They already have. The question is whether your organization is treating its operating knowledge as a thing worth governing.
If your organization has fifteen Teams threads and fifteen agent instruction files, you already know what the gap costs.
Building the spine is less work than living without it.
 | A guest post by
|