
In Agentic Design, Research Is Load-Bearing
The research doesn't change what we build. It changes whether what we build is worth trusting.

We’ve shipped things we shouldn’t have. Everyone in this industry has. A receiving screen that added a confirmation step nobody asked for, a notification system that treated everything as urgent, a report built for a manager that pickers were expected to read. The difference is that those mistakes were fixable. A bad screen is a bad screen. You find out, you fix it, you move on.
That is not the situation we are in now.
The systems we are building don’t just display information. They make decisions—and then they ask someone to act on them.
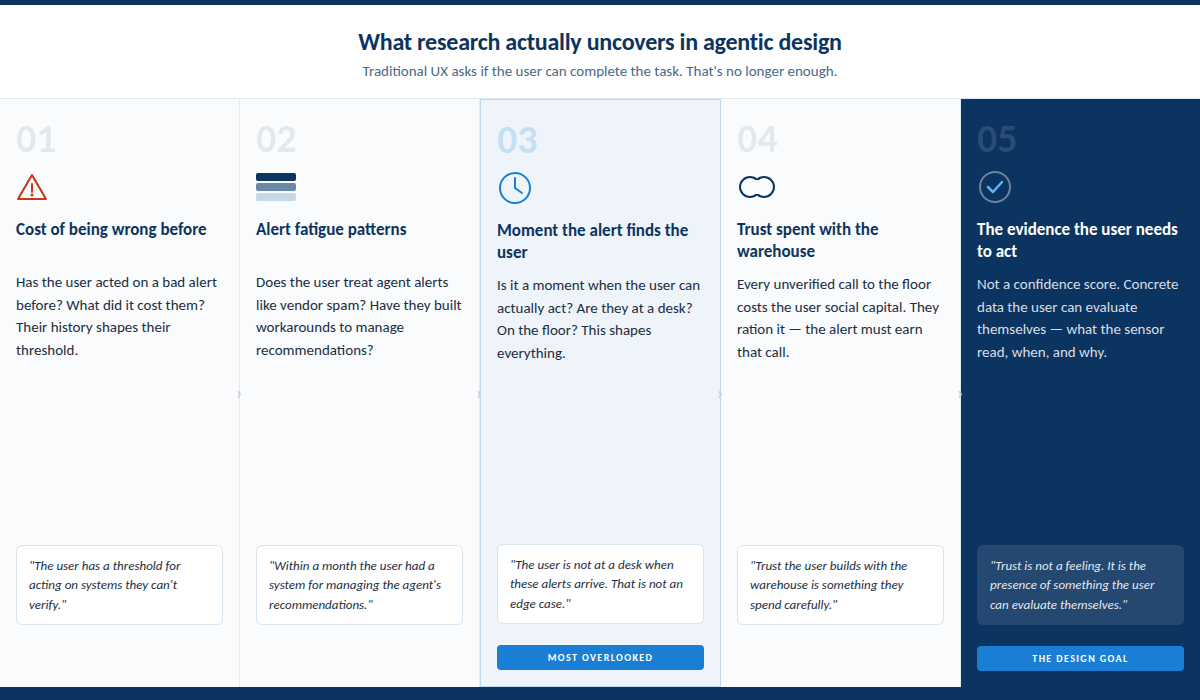
An AI agent correlates a temperature sensor anomaly with a pallet of frozen dinners in cold storage and surfaces a recommendation: pull the shipment. The planner has no way to know if it’s right. All he sees is: Pull shipment. Recommended action: hold.
He’s not sure he trusts it. He can’t verify it. The WMS doesn’t hold that kind of information, and calling the warehouse over something that might be nothing is a conversation he’d rather not have. He closes the alert and goes back to work.
That’s not the end of the story. The next alert comes in and he opens it a little slower. The one after that he flags to check later. Within a month he has a system for managing the agent’s recommendations—skimming, filing, occasionally acting when the stakes feel obvious enough.
The agent hasn’t changed. The model is still running. The data pipeline is still clean. But somewhere between the first ignored alert and the twentieth, the system stopped being a decision-support tool and became background noise.
Two Ways It Goes Wrong
That’s one failure mode. The planner doesn’t trust the system, bypasses it, and the organization’s investment in the agent goes down the drain, one ignored notification at a time.
The other failure mode is worse. The planner does trust it. He acts on it, puts a pallet of product on hold that was never at risk, spends too much time on the phone with the vendor, and has a conversation with his boss that he does not want to have.
Both failures have the same cause. Nobody had asked what this planner actually needed—what information would move him from alert to action. The agent failed him not because it was built badly, but because it was built without him.
Skipping the research doesn’t make the problem go away. It just means the product solves it badly in front of a user who will not give it a second chance.
A bad screen gets a second chance in the next sprint. Trust in an agentic system does not.
What Research Actually Does Here
It is not the same question we have always asked. Traditional UX research wants to know if the user can complete the task. That is still worth knowing, but it isn’t enough anymore.
With an agentic system, the question is whether the planner will act on the recommendation—and that depends on things that never show up in a workflow diagram. It depends on what it has cost him to be wrong before. On whether he has learned to treat automated alerts the way he treats annoying email from vendors. On whether the moment the alert finds him is a moment when he can actually act.
None of that comes out in a usability test. It comes out when you sit with him long enough to understand that the trust he’s build with the warehouse is something he spends carefully, that he has a threshold for acting on systems he can’t verify, and that he is not at a desk when these alerts arrive. Those are not edge cases. They are the reason the design failed.
The team that built the agent had a version of the same problem. They had a persona. They had a workflow map. The pain points felt obvious. So the research became a box to check rather than a question to answer—because they already thought they knew what they’d find.
The planner couldn’t evaluate the recommendation because he couldn’t see the reasoning behind it. The team couldn’t evaluate their design because they hadn’t seen his reality. Both were working from incomplete information and thought they had enough.
That’s what doing research actually means. The team needed to go beyond a quick chat with the planner. They needed to understood the cost structure of his job before they decided what the recommendation should look like.
The Evidence He Needs
For the planner, trust is not a feeling. It is the presence of something he can evaluate himself.
What would move him to act at 6am, when he gets an alert that says Pull shipment. Recommended action? Not a confidence score. Not a longer explanation. Concrete evidence—what the sensor actually read, when, and how that compares to the threshold that matters for this product. Something that lets him assess the recommendation rather than simply accept or reject it.
Or a note from the floor. “Unit was running warm at 2am, back to normal now, but worth watching.” That lands differently than sensor data, even if it’s saying the same thing. It comes from someone with direct knowledge, which changes the calculation entirely.
Both are examples of the same principle: the design failure wasn’t that the alert was too short or too long. It was that it asked the planner to trust a conclusion without giving him the evidence to make a decision himself. That is what breaks trust in an agentic system, an unexaminable suggestion.
The Excuse Is Gone
The tools are faster. A testable concept that used to require a sprint can be generated in an afternoon. An unmoderated study comes back overnight. The time excuse is gone.
The real reason is harder to say out loud. Teams don’t ask because they’re not sure they want to know. If the roadmap is set and the agent is being built, research might surface something that’s true, inconvenient, and too late to act on. So the question doesn’t get asked.
That calculus made more sense when a bad screen was the worst outcome. It doesn’t make sense anymore. The research doesn’t change what we’re building. It changes whether what we build is worth trusting.
NOTE: This piece was developed with the assistance of AI. The perspective, judgment, and conclusions are my own. The tools are new and powerful; the responsibility for thinking, judgment, and meaning remains human.